Endpoint Status
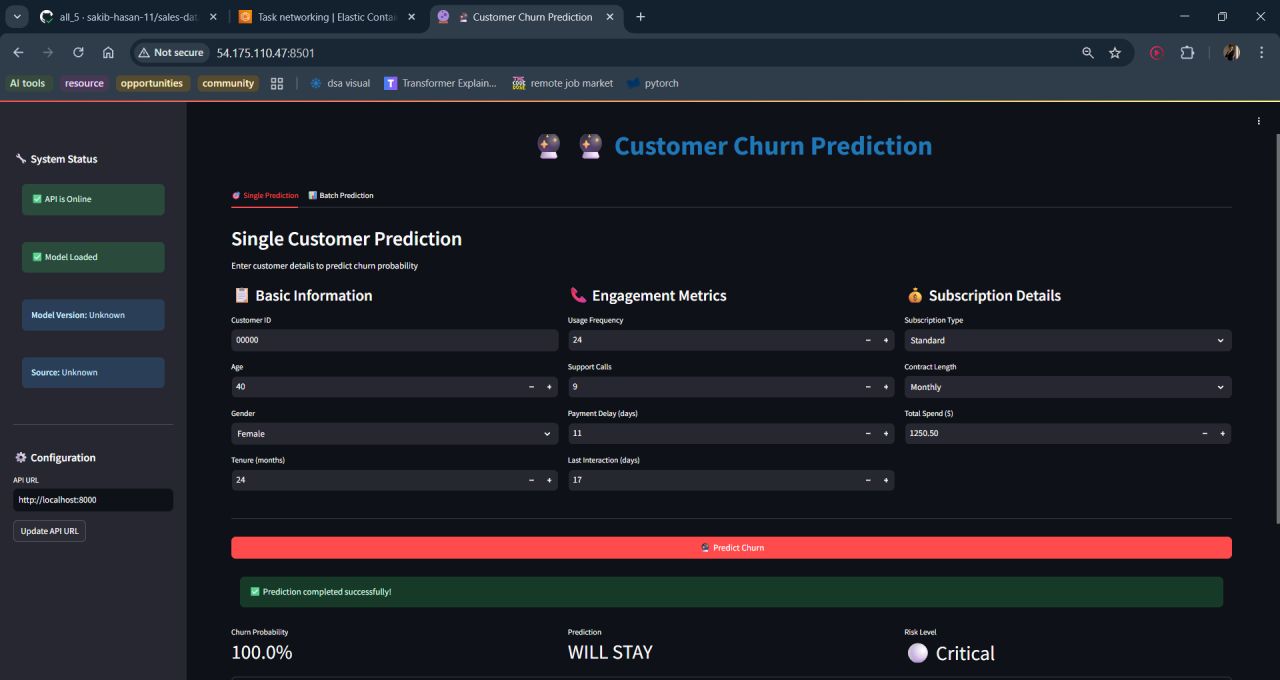
Try the Churn Prediction Model
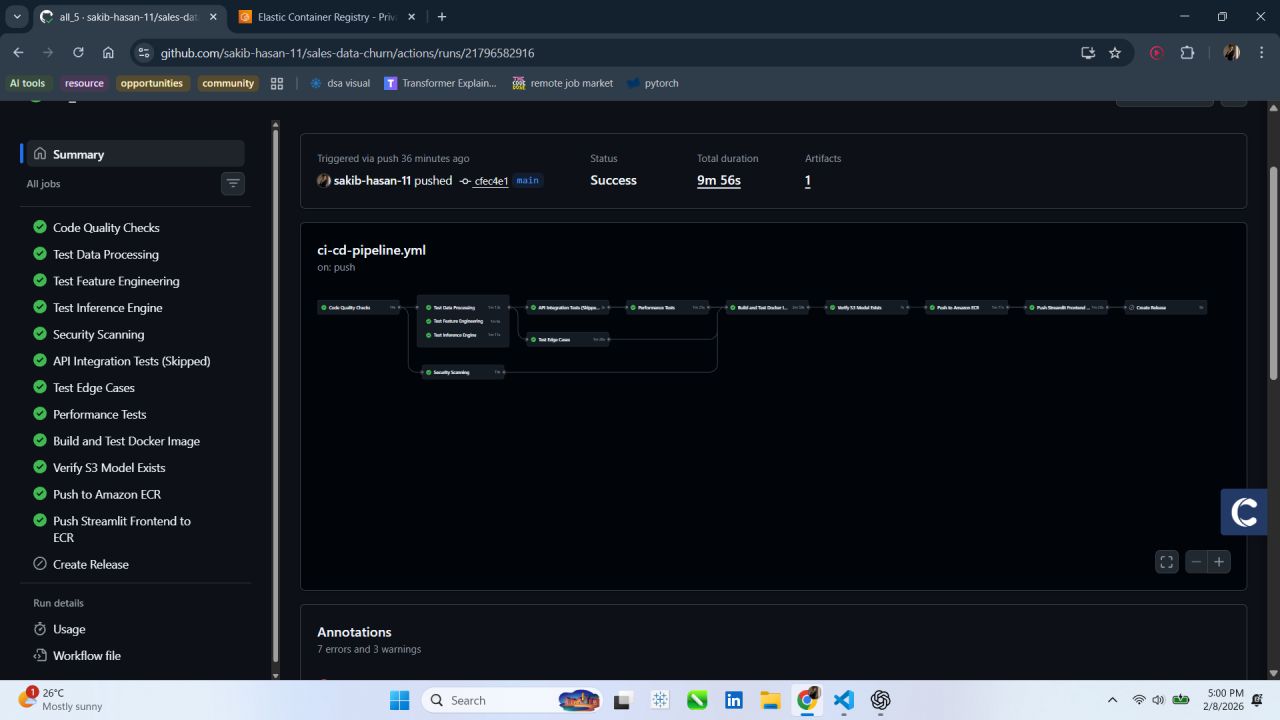
ECS CLOUD ENDPOINT IS NOT RUNNING TO REDUCE COST.
The FastAPI inference service is configured and containerised but the ECS task is kept stopped to avoid idle cloud charges.
The screenshots below show the live API in action — spin it up locally with docker run from the GitHub repo.